不少开发者遇到 Claude Code 连接超时,第一反应是重装客户端或换 API Key,但多数情况下问题既不在本地安装,也不在密钥——命令行工具是好的,模型也在线,只是一次请求在长时间停顿后失败,因为底层的 HTTP 流没能在默认请求窗口内把数据传完。对离 API 服务器较远的开发者来说,真正的瓶颈在网络链路:偏高的往返延迟、拥塞路径上的丢包,以及中途被切断的 TLS 连接。本文拆解 Claude Code 连接超时背后的成因,教你在网络层把它定位出来,并说明 NasaCode 如何稳定到 API 的链路,让长时间的 agent 运行不再跑到一半中断。
应用层的建议——精简上下文、切换更轻的模型、重启会话——只能解决一部分超时。但当同一条命令在一个网络下能成功、换个网络就超时,差别就在数据包走的那条路,而不在你的提示词。这一层正是本文要讲清楚的。
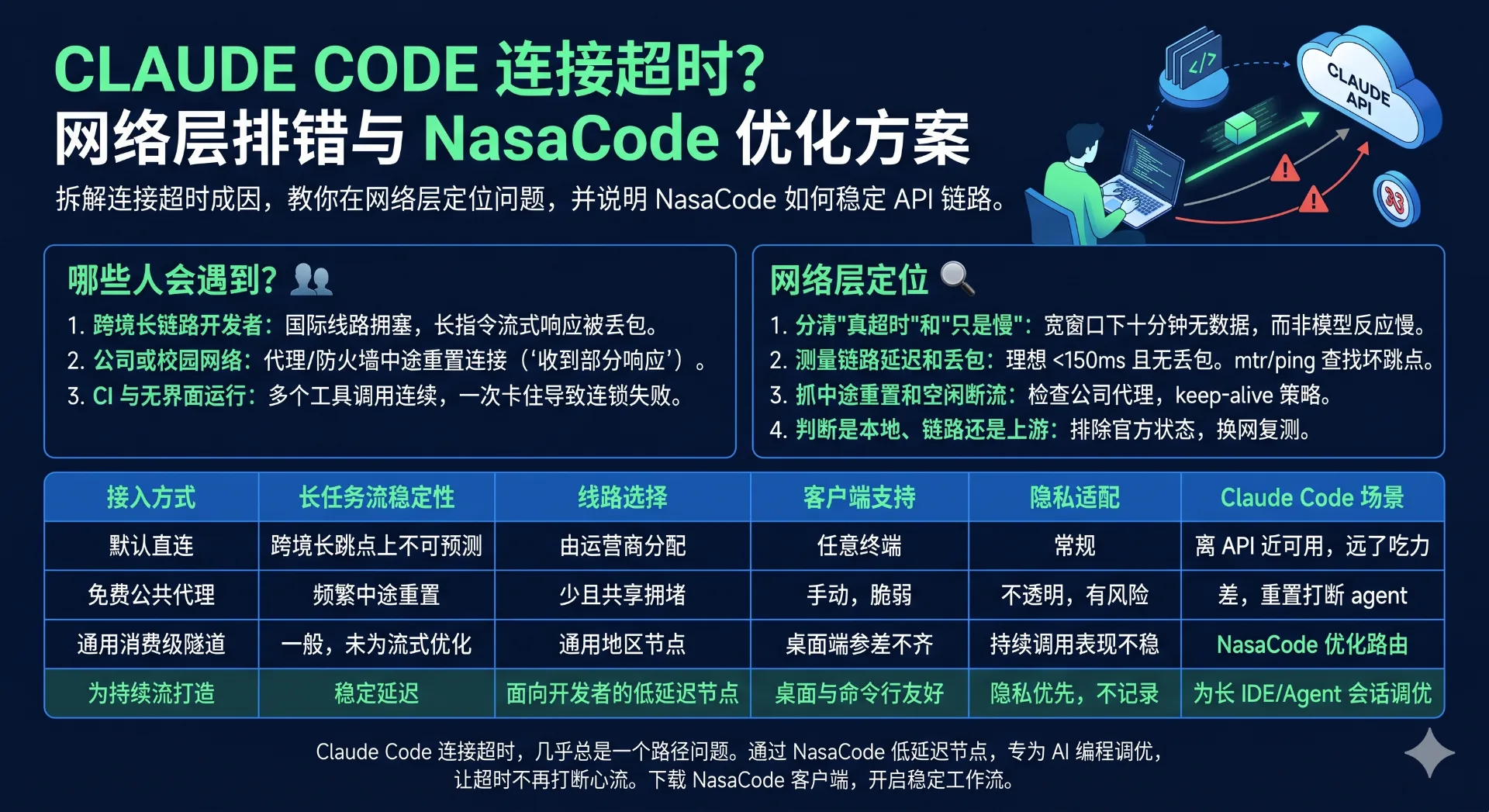
哪些人会遇到 Claude Code 连接超时
最典型的是跨境长链路的开发者。流量要先穿过一段很长、又拥塞的国际线路才能到达 API,于是在做大型重构时,光标长时间不动,最后弹出"请求超时",而之前的短指令明明一切正常。模型其实在生成,只是回传的 token 流在丢包的路径上推不动。
第二种常见场景是公司或校园网络。这里的连接往往在响应中途被重置,也就是那条让人头疼的"收到部分响应"——因为中间的代理或防火墙缓冲了流式数据,或者太激进地关掉了它认为空闲的连接。第三种是 CI 与无界面运行:一个 agent 连续发起几十次工具调用,只要其中一次往返卡住,就会连锁导致整个任务失败。三种情况的共同点是:请求始终没有干净地走到结束,客户端只好放弃。
在网络层定位 Claude Code 连接超时
先分清"真超时"和"只是慢"
先确认失败的性质。Claude Code 给请求留了相当宽的窗口(默认在十分钟量级),所以一次真正的连接超时意味着这段时间内流没产出任何可用结果,而不是模型单纯反应慢。先跑 claude --version 确认版本是新的,再用 /doctor 一次性体检,它能暴露大部分配置问题。然后发一条最简单的一句话提示。如果小请求秒回、而大型 agent 任务超时,说明链路是通的,问题出在弱链路上承载不了大流量,而不是服务故障。
测量链路上的延迟和丢包
这一步是大多数排错文章会跳过的关键。用 ping 测到 API 主机的基准往返时间,再用 traceroute 或 mtr 看丢包是在哪一跳冒出来的。交互式写代码理想的往返时间最好稳定在 150 毫秒以内、几乎不丢包;一旦超过 250 毫秒还在某个中间跳点间歇丢包,流式响应就会卡顿,长调用也开始触发超时。抖动和纯延迟同样要命:一条在 80 毫秒和 400 毫秒之间来回跳的路径,会让流毫无规律地断。如果 mtr 显示丢包出现在某个运营商跳点上,那就是路径本身的问题,任何客户端参数都救不了一条坏路径。
抓中途重置和空闲断流
"收到部分响应"是连接层的特征,而不是模型报错。它意味着承载流式答案的 TLS 连接在最后一个 token 到达前就被切断了——通常是某个会缓冲的代理,或者一旦模型停顿思考就把连接掐掉的空闲策略。检查一下是否有公司代理挡在流量前面、keep-alive 是否被剥掉、同一条提示在别的网络上能否跑完。当这种重置在换掉公司线路后消失,你就把它锁定到那条路径上了。
判断是本地、链路还是上游
按顺序逐层排除。官方状态页能告诉你 API 本身是否在降级;如果是绿的,故障就在应用层以下。换用手机热点或另一个网络复测一次——如果 Claude Code 连接超时随之消失,那你的主用线路就是问题所在。NasaCode 正是处理这中间的一层:与其让数据包在拥塞的默认路径上乱走,不如把流量固定到一条延迟更稳、丢包更低的优化路由上,让流活得够久,大型 agent 任务才能跑到底。
不同接入方式对比
| 接入方式 | 长任务流稳定性 | 线路选择 | 客户端支持 | 隐私 | 适配 Claude Code |
|---|---|---|---|---|---|
| 默认直连 | 跨境长跳点上不可预测 | 由运营商分配 | 任意终端 | 常规 | 离 API 近时可用,远了吃力 |
| 免费公共代理 | 频繁中途重置 | 少且共享拥堵 | 手动,脆弱 | 不透明,放密钥有风险 | 差,重置会打断 agent |
| 通用消费级隧道 | 一般,未为流式优化 | 通用地区节点 | 桌面端 | 参差不齐 | 持续调用时表现不稳 |
| NasaCode 优化路由 | 为持续流打造的稳定延迟 | 面向开发者的低延迟节点 | 桌面与命令行友好 | 隐私优先,不记录流量 | 为长时间 IDE 与 agent 会话调优 |
常见问题
把超时时间调大能解决吗?
很少能。更长的窗口只有在流确实快传完时才有用。如果在丢包或连接被重置,调大超时只是让你等更久去迎接同一个失败。先把路径修好。
换一台更快的电脑有用吗?
没用。超时是网络事件——字节正在你的终端和 API 之间飞行。CPU 和内存影响本地工具跑多快,而不决定响应流能否熬过一个丢包的跳点。
怎么判断是官方故障还是我自己的网络?
先看官方状态页。如果它显示健康、而最简单的提示仍然失败或卡住,故障就在你的线路上。换个网络复测,一分钟内就能确认。
怎么让长时间的 agent 运行不超时?
每一步的负载控制在合理范围,但更重要的是跑在一条延迟稳定、丢包低的路由上。一条稳的连接,才能让多步 agent 任务从头到尾把流保持住。
Claude Code 连接超时,几乎总是一个穿着应用层外衣的路径问题。一旦你去测延迟和丢包、而不是靠猜,解法就很清楚:把路径稳住。NasaCode 就是为此而生——低延迟节点,专为 AI 编程工具产生的那种持续流式流量调优,让你的会话在最长的重构里也保持在线。
下载 NasaCode 客户端,把你的 Claude Code 工作流接到一条优化路由上,让超时不再打断你的心流。